Voici un article sur quelque-chose que je viens de découvrir un peu par hasard, et qui m’a un peu voir beaucoup surpris ! On en apprend tous les jours, et aujourd’hui je le partage !
Les Captcha ou le double effet KissCool
Tout le monde connaît et a eu affaire aux Captcha sur des sites web ou formulaires de contact : ces petites cases vous posent des questions afin de prouver que vous êtes bien un humain et non une machine. Rien de sensationnel dans tout cela, cela sert juste à éviter les méchants spammers d’envoyer des messages de pub via les formulaires en ligne non ?
Et bien oui et non comme on va le voir !
Détournement de la fonction originale
Les Captchas ont peu a peu ajouté des « fonctionnalités » a leur but initial. Voici un petit aperçu de cette évolution.
Niveau 0 – pas encore de détournement
Pour la petite histoire, les captcha ont été inventés en l’an 2000 dans une université américaine. Le terme CAPTCHA est l’acronyme de Completely Automated Public Turing test to Tell Computers and Humans Apart (test public de Turing complètement automatique afin de différencier les humains des ordinateurs). A l’origine vers les années 50, le test de Turing tentait tout simplement de répondre à la question : « une machine peut-elle penser ? ».
Les captcha de cette époque était juste des questions du type » 3 + 4 = ? « .
Niveau 1 – transcription de textes en travail dissimulé
L’un des inventeurs du Captcha se dit qu’il pourrait mettre à profit les interactions avec les humains (estimés à 200 million par jour en 2006) pour aider l’intelligence artificielle à « retranscrire » des textes scannés.
Google repère cette opportunité qui s’ouvre et rachète reCaptcha en 2009.

Google a depuis sa création la volonté de créer le plus grand ensemble de contenu numérisé existant. reCaptcha va lui permettre de combler les lacunes de l’IA de son système reconnaissance de caractère.
Les captcha ont donc été composés de deux mots à retranscrire : l’un d’eux est connu par la machine, et l’autre non. Si le mot connu est entré correctement, alors le second est enregistré. Si plusieurs utilisateurs donnent la même retranscription au mot inconnu, alors celui-ci est validé.
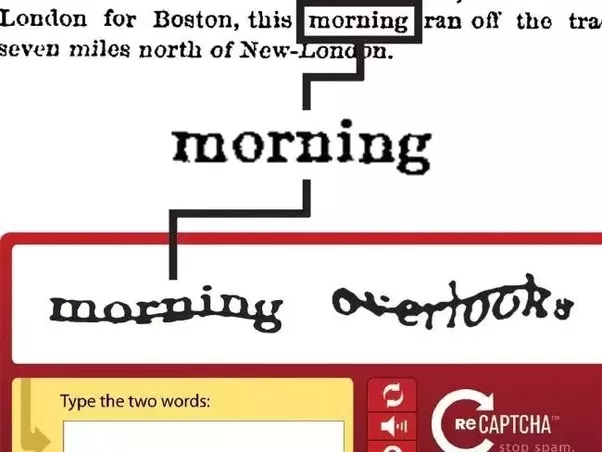
Ce process a duré environ deux ans, puis a du être modifié pour deux raisons :
- l’intelligence artificielle de transcription est devenue « trop » efficace (les mots restant trop difficile à déchiffrer même pour les humains),
- toutes les ressources numérisables l’ont été en 2011 (tous les références de Google Books ainsi que l’intégralité des 13 millions d’articles de presse du New York Times depuis 1851 entre autre !).
Que faire alors de toute ces secondes de cerveaux disponibles ?
Niveau 2 – collecte de données pour Google Maps
A partir de 2012, l’intelligence « collective » est utilisée pour la reconnaissance d’image, bien moins perfectionnée alors que pour l’OCR.
Google commence par street view, avec le même système de validation de l’utilisateur que précédemment (c’est tout de même le but des captcha il ne faut pas l’oublier !), mais avec un deuxième mot à reconnaitre provenant d’une image de street view, par exemple des numéros de maison ou des panneaux de signalisation.
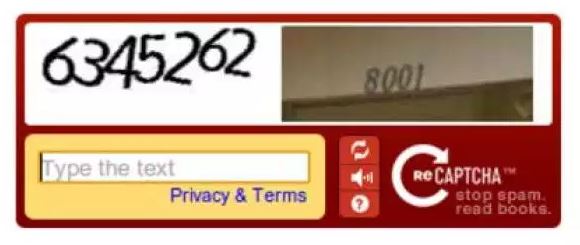
Les données collectées à force de secondes « volées » aux utilisateurs (moins de temps serait nécessaire par personne pour la seule validation humain/robot, ce temps supplémentaire est estimé à 250 000 heures par jour en 2006) sont ajoutées à la base de donnée de Google Maps. Pratique non ?
Pourtant, comme on l’a vu ci-dessus, les machines peuvent réussir à résoudre ce type de captcha : le système était bien pour Google Maps mais ne répondait plus au besoin initial. Il a donc fallu inventer de nouveaux systèmes de tri.
Niveau 3 – double but pour la nouvelle version de reCaptcha
En 2014, fini les mots ou les chiffres à taper : il y a juste une case à cocher ! Pratique !
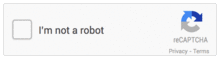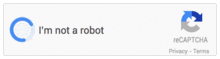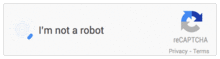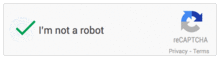
Comment cela fonctionne-t-il ? Les outils de reCaptcha sont-ils devenus devins pour savoir en un clic si vous êtes humains ou non ?
Afin de savoir si vous êtes ou non un robot, les outils de Google sont mis en place non plus juste sur le formulaire à « protéger ». L’analyse des comportements des visiteurs sur la page est étudié, grâce au temps passé pour remplir le formulaire ou avec les mouvements de souris, mais les cookies ou les paramètres du navigateurs sont aussi passés en revue. Tout cela permet de déterminer si vous êtes plutôt du genre robot ou humain.
3.1 : marketing comportemental
Fini le travail dissimulé alors ? Au contraire : au lieu d’être un travailleur anonyme, votre travail est personnalisé. Grâce aux cookies de votre navigateur, vous êtes identifiés et votre comportement sur chaque site « équipé » est enregistré et vient compléter votre profil. Si vous n’avez pas de compte Google connecté, alors les cookies sont tout de même utiles pour remplir une sorte de shadow profile, qui pourra peut-être être relié plus tard à votre véritable profil et qui en attendant donne des informations sur les comportements globaux des internautes.
Si votre navigateur est paramétré pour être bien « protégé » contre ces méthodes de pistage, alors vous leur êtes totalement inutile : vous êtes donc fichés comme « suspect » et cocher la case ne fonctionne pas : on vous renvoie vers la caisse pour payer le captcha du site que vous visitez : direction les cases à cocher !
3.2 : nourrissage de réseaux neuronaux
Ce n’est pas une blague ! Si pour les raisons évoquées si dessus ou tout simplement si Google en a besoin, alors vous êtes redirigés vers les cases à cocher de ce type là :

Et comme vous l’avez peut-être remarqué, généralement il n’y en a pas qu’un à remplir. On se dit généralement « merde j’aurai dû mettre le haut de la 3e case je me suis trompé » en fait pas du tout : certaines grilles sont connues et permettent de vous classifier humain ou non, tandis que d’autres sont juste du travail bonus ! Et quel est le job ? Entraîner un réseau neuronal d’un système d’intelligence artificielle !

Saurez-vous distinguer un feu rouge d’un lampadaire ?
Comment cela fonctionne-t-il ? l’IA n’est au début pas vraiment intelligente : tout comme les humains au cours de leur vie, pour reconnaitre un feu rouge par exemple il faut que savoir à quoi ça ressemble généralement, pour définir quelques caractéristiques communes de ceux-ci : on est ensuite capable de reconnaître un feu rouge dans a peu près n’importe quel pays par la suite, et les différencier des lampadaires sans trop de problèmes. Et bien c’est pareil pour l’IA, il faut lui apprendre ou vérifier ce qu’elles ont appris et c’est ce que font les internautes en cochant les cases des captchas : c’est le deep learning.
Quelle utilisation pour l’Intelligence Artificielle que nous participons tous à former ?
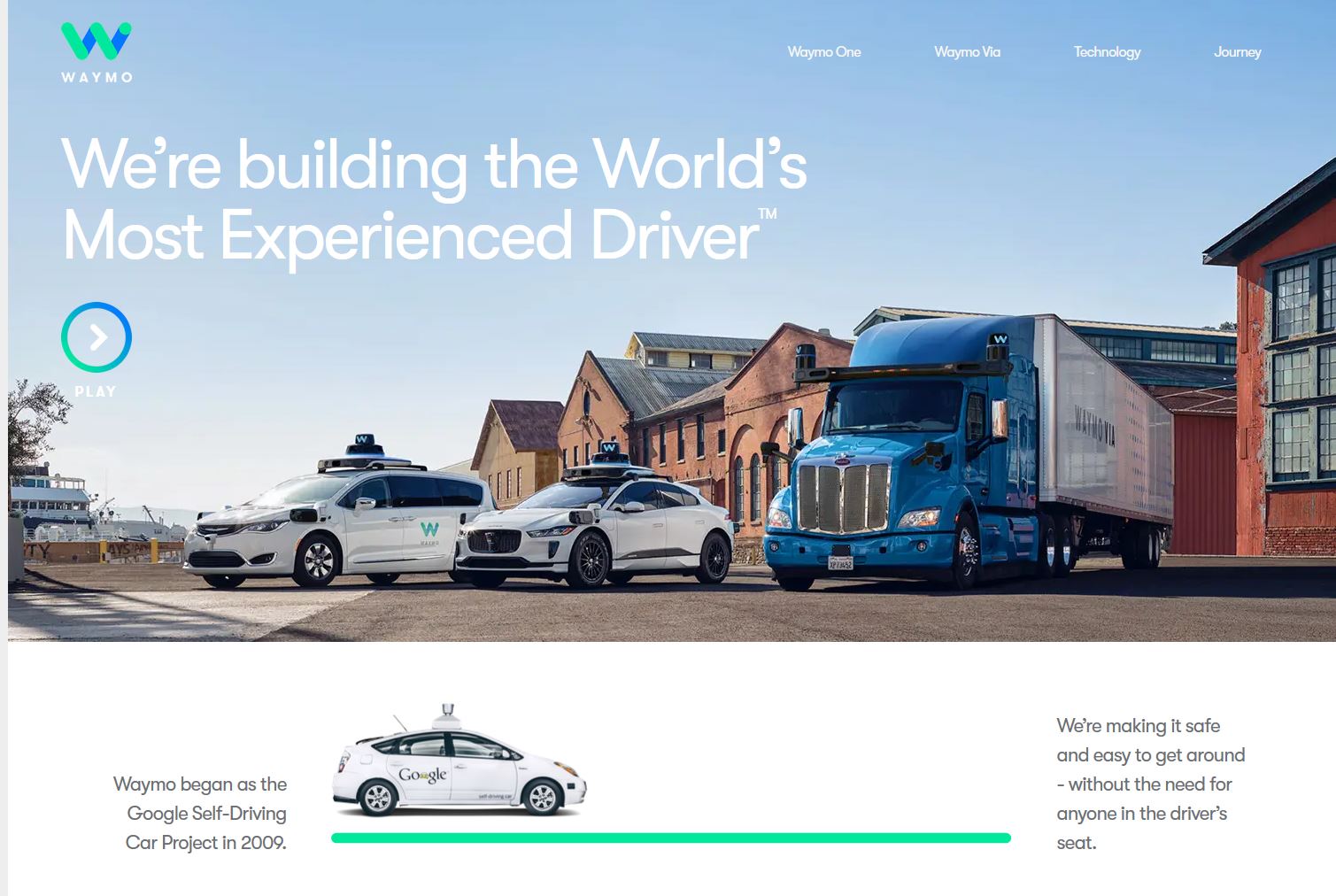
Site internet de Waymo, la voiture autonome de Google
Comme on pouvait s’en douter avec les panneaux de signalisation, passages piétons et autres infrastructures routières que l’on doit reconnaitre dans les Captcha, c’est dans le domaine de la voiture autonome que les logiciels sont à présent entraînés. Le slogan de Waymo aurait d’ailleurs pu être « You‘re building the World’s Most Experienced Driver » !
En tout état de cause, il semblerait aujourd’hui que Google n’ai plus besoin trop besoin de nous pour les voitures, car il lance sa nouvelle version de reCaptcha : que nous réservent-t-ils pour la suite ?
Niveau 4 – data mining
Le nouveau système, appelé « No Captcha Recaptcha » annonce fièrement qu’il n’est désormais plus nécessaire ne serait-ce que de cocher une case pour savoir si l’on est un robot ou non. Il s’agit tout simplement d’une évolution de la première étape de leur système précédent : analyse du comportement et de l’historique, mais cette fois-ci appliquée à toutes les pages du site (et de toutes celles des autres sites visités avant grâce aux cookies). Il vous est ensuite attribué une note en fonction du risque potentiel que vous présentez.
La vidéo de présentation de l’outil est très claire : plus l’outil est mis en place largement sur le site, plus il sera efficace. Il faut qu’il soit en mesure de scanner toutes les interactions avec les utilisateurs pour détecter les robots.

« Les utilisateurs ne sont plus dérangés, tout le monde est content, sauf les robots ! ». Et les plus heureux sont sûrement les analystes de Google, qui peuvent désormais compter sur une quantité impressionnantes de données comportementales sur un maillage de millions de site web différents, afin rendre leurs activités toujours plus rentables (il faut rappeler que 75% des 30’700’000’000 de dollars de bénéfices de Google en 2018 proviennent de la publicité).
En conclusion
Est-il si gênant que cela de perdre quelques secondes par-ci par là ? Pourquoi ne pas profiter tout simplement d’un internet gratuit grâce à ces entreprises du web qui ont trouvé un business model qui profite à tout le monde ?
Je ne le souhaite pas personnellement. D’une part, rien n’est vraiment gratuit et les milliards de bénéfices ont bien été payés par quelqu’un. D’autres part tout le monde se retrouve à payer le prix de la surproduction, elle-même conséquence de notre société basée sur la croissance infinie de la consommation – et de son moteur, la publicité toujours plus efficace pour créer nos besoins.
Lutter à son niveau contre la publicité -directe ou indirecte – est une lutte contre cette forme de société.
Le sujet de la conclusion nécessiterait bien plus que trois ligne pour être traité correctement et convaincant, mais ce n’est pas le but de l’article ! Si vous avez pu vous rendre compte d’une des nombreuses méthodes utilisées pour faire tourner la grande machine des GAFA, alors c’est tout bon !
 Pour aller plus loin dans les rouages des géants du net, et par conséquent dans les coulisses de nos vies numériques actuelles, je vous conseille le livre « Capitalisme de plateforme« , ouvrage très pointu dans le domaine de l’économie traitant des conditions qui ont permis l’émergence et le développement des grandes plateformes numériques (entre autre les GAFA – Google Apple Facebook Amazon), puis détaille leur mode de fonctionnement pour comprendre quel est « pour de vrai » leur modèle économique.
Pour aller plus loin dans les rouages des géants du net, et par conséquent dans les coulisses de nos vies numériques actuelles, je vous conseille le livre « Capitalisme de plateforme« , ouvrage très pointu dans le domaine de l’économie traitant des conditions qui ont permis l’émergence et le développement des grandes plateformes numériques (entre autre les GAFA – Google Apple Facebook Amazon), puis détaille leur mode de fonctionnement pour comprendre quel est « pour de vrai » leur modèle économique.
PS : je viens de retirer « voici un petit article » du premier paragraphe. Si j’en doutais encore, il faut que je me rende à l’évidence : je ne sais pas écrire de petits articles, rapides et efficaces, il faut toujours que j’aille chercher la petite bête et comprendre tout dans les moindres détails… J’ai pourtant fait des efforts, et il reste sûrement quelques zones d’ombres, erreurs ou omissions que vous me pardonnerez ! :)
 Louison Menoux
Louison Menoux
Merci, très instructif !!